Instant speech-to-text—available in 137 languages and counting.

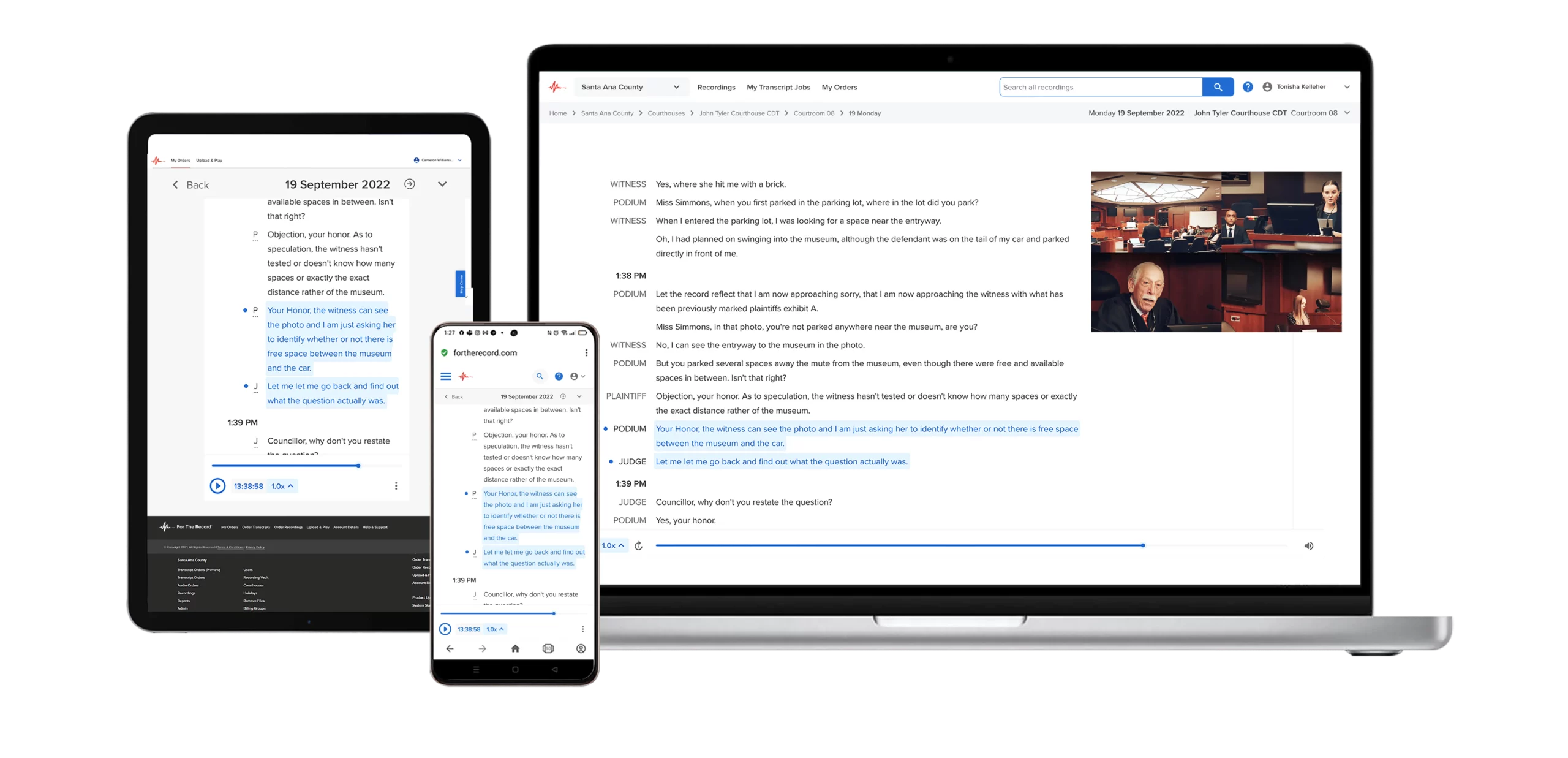
Building on decades of innovation in digital court recording technology, For The Record has once again redefined how the court record is captured and accessed. FTR RealTime, powered by FTR Justice Cloud, transforms live courtroom proceedings into a searchable and secure cloud-based record—available the moment words are spoken.
Contact Us Download Product SheetThis real-time speech-to-text capability represents the most advanced way to increase accessibility in modern courtrooms—displaying live transcription through the Display App across multiple screens for immediate visibility. It supports ADA Title II compliance by ensuring courts have an on-demand accessibility option for people who are deaf or hard of hearing.
FTR RealTime enables authorized participants to follow, search, and engage with the record as events unfold, whether in the courtroom or remotely. It makes official recordings instantly accessible and searchable, streamlining transcription, review, and evidentiary processes.
At the same time, court staff can monitor sessions, annotate hearings, and manage proceedings as they happen to ensure accuracy, control, and efficiency throughout the court process.
At its core, FTR RealTime harnesses advanced automatic speech recognition (ASR), underpinned by artificial intelligence, to capture, process, and transcribe courtroom speech with exceptional accuracy and speed. Our speech-to-text software for courts converts spoken words into written text by first capturing audio and filtering out background noise and other irrelevant sounds to isolate the speech.
Advanced machine learning models then analyze the processed or “cleaned” audio, break it down into smaller sound units, and map those units to the most probable sequence of words. Natural language processing interprets context and meaning, ensuring a more accurate and readable transcript.
The system processes accents, dialects, multiple languages, complex legal terminology, and even overlapping dialogue using multi-pass processing to deliver up to 95% accuracy in real time. It maintains a precise, verifiable link between audio, video, and text, ensuring that the original recording remains the definitive source of truth.

Supports 130+ languages and dialects with user controls, instant language detection, and transcript regeneration using the correct language model
Justice in real time—audio and text, perfectly in sync. FTR RealTime is designed to improve accessibility and offer an easily searchable, digital record in real-time right at your fingertips. Request a personalized demo today or speak with one of our experts about transforming your courtroom administration.
Contact Us